Yikes. I’ve been working in my lab all night and completely lost track of the time. It’s now about 2AM.. and I realized that I hadn’t blogged. I’ve spent many hours in my lab during this break.. I realize just how much I love just tinkering in there.. If only I could make a living doing that.
I had a good quiet day.. not too much to report.. The four of us had a nice sushi lunch together midday.. and that was about it.
It’s too late to write much more.. but I did want to report on another hacking project I took on over this break.. I wrote a simple web page extractor in Python and managed to capture all of the text of my first two years of blogging. (here’s the code if anyone is interested )
from BeautifulSoup import BeautifulSoup
import re, urllib2
output_file = file(‘outputdata.txt’,’w’)
def remove_html_tags(..
p = re.compile(r’<.*?>‘)
return p.sub(”, data)
def remove_extra_spaces(..
p = re.compile(r’..s+’)
return p.sub(‘ ‘, data)
def read_entry(year,month,day):
url = “http://blog.myspace.com/index.cfm?fuseaction=blog.view&FriendID=105120181&blogMonth=” + str(month) + “&blogDay=” + str(day) + “&blogYear=” + str(year)
print url
date = str(month) + “/” + str(day) + “/” + str(year)
print date + ‘..n’
output_file.write(date + ‘..n’)
try:
resp = urllib2.urlopen(url,None,100)
output_file.write(url + ‘..n’)
html_code = resp.read()
soup = BeautifulSoup(”.join(html_code))
subject= soup.find(“p”, { “class” : “blogSubject” })
if subject != None:
subj = remove_extra_spaces(remove_html_tags(str(subject.contents1)))
print subj + ‘..n’
output_file.write(subj + ‘..n’)
anyP = 0
table = soup.findAll(“table”, { “class” : “blog” })
allP = table0.findAll(“p”)
for p in allP:
anyP = 1
cont = remove_extra_spaces(remove_html_tags(str(p)))
print cont + ‘..n’
output_file.write(cont + ‘..n’)
if anyP == 0:
print “… Empty content..n”
except IOError, e:
print e.reason
for day in range(25, 31):
read_entry(2006,11,day)
for day in range(1, 32):
read_entry(2006,12,day)
for year in range(2007, 2009):
for month in range(1, 13):
for day in range(1, 32):
read_entry(year,month,day)
It was fun figureing out how to do that because @$%ing MySpace doesnt’ have an export feature.. that means you can’t back up you blog.. Now I have a backup of all the text.. Just like last year, I found a program to analyze the text just for fun.. O fhte half a million words.. here’s what Wordle.com made of my blog. The bigger the word, the more frequently it was mentioned… Take a look…
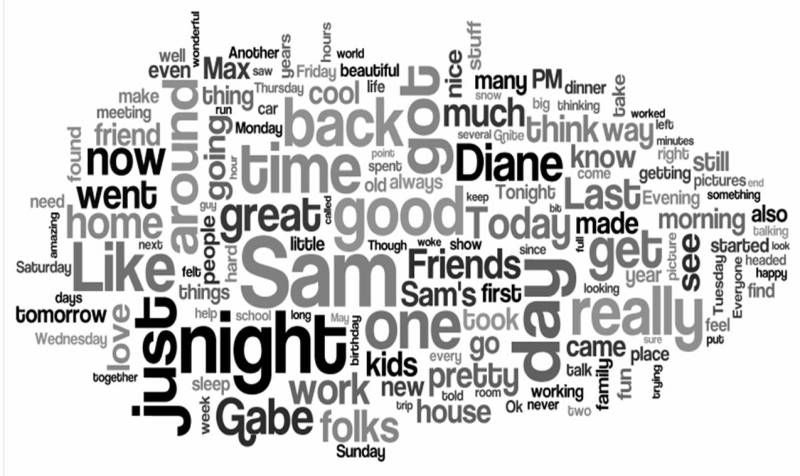
The more I starte a ttit.. the more I think it reallydoes sonme up the second year ….
OK.. I gotta sleep now.. More tomorrow.. G’note all. G’nite Sam !
-me